

?? 由 文心大模型 生成的文章摘要
相信很多人都有過這樣的經(jīng)歷:來到一個自己不熟悉的場景,特別是在一些GPS信號不準(zhǔn)確的室內(nèi)場所,很難找到建筑物內(nèi)部的一些特定地點。本文將以幫助用戶在大型機場等場所中快速找到上車點為出發(fā)點,介紹滴滴AR實景導(dǎo)航產(chǎn)品研發(fā)過程中的挑戰(zhàn)和關(guān)鍵技術(shù)。
1.
應(yīng)用背景
我們在用戶調(diào)研中發(fā)現(xiàn),在一些大型的機場、商場、火車站內(nèi)部,滴滴乘客在下單成功之后,往往需要更多的時間才能找到上車點,其主要原因是在這些大型的室內(nèi)場所中,GPS信號不準(zhǔn)確,而這些建筑往往面積很大、內(nèi)部路線復(fù)雜,當(dāng)乘客對場景不熟悉時,找到上車點存在很大的困難。為了解決這個問題,地圖團(tuán)隊提出了“圖文引導(dǎo)”的方式來幫助用戶,通過特定場景的圖片和文字的方式相結(jié)合來引導(dǎo)用戶找到上車點。與此同時,我們也在持續(xù)探索是否有更加直觀、易理解的方式來幫助用戶,受到增強現(xiàn)實(AR)技術(shù)在游戲中應(yīng)用的啟發(fā),我們提出了使用AR的方式來幫助用戶找到上車點,最終開發(fā)出了滴滴AR實景導(dǎo)航產(chǎn)品。
當(dāng)乘客在支持AR導(dǎo)航的場站,使用滴滴出行App選擇推薦上車點發(fā)單成功后,可以通過產(chǎn)品界面中的AR按鈕進(jìn)入導(dǎo)航界面,并按指引操作,體驗在AR元素指引下到達(dá)上車點。如下圖所示。
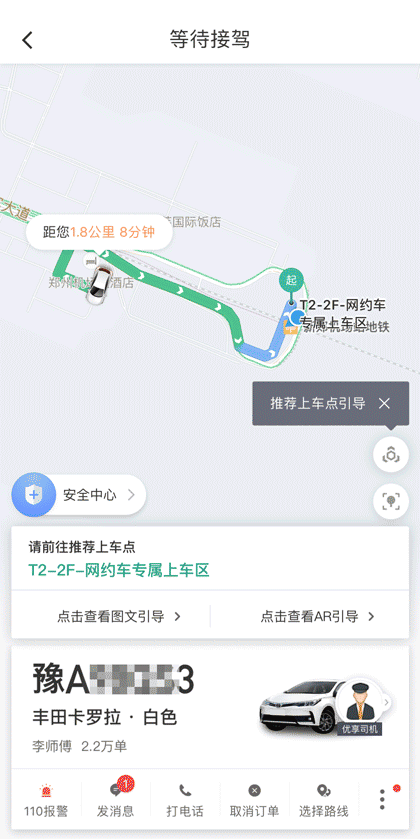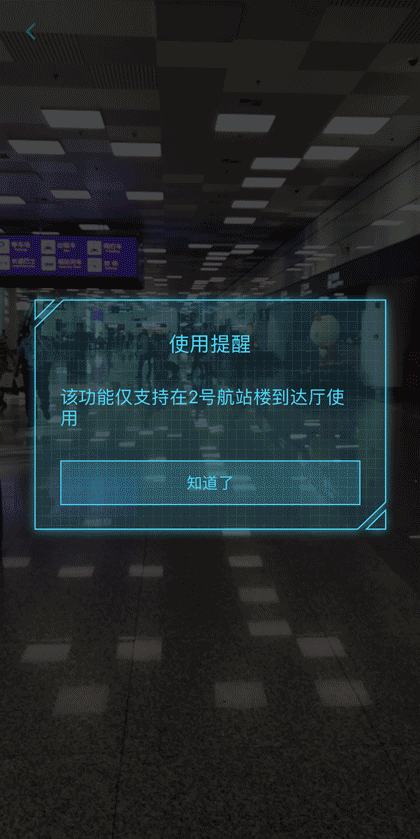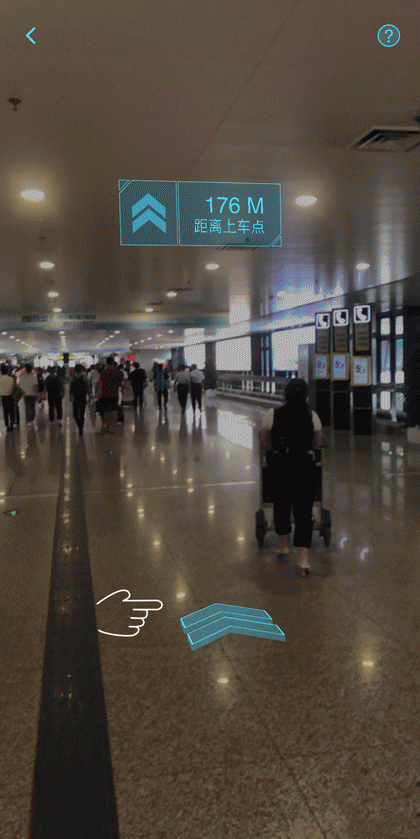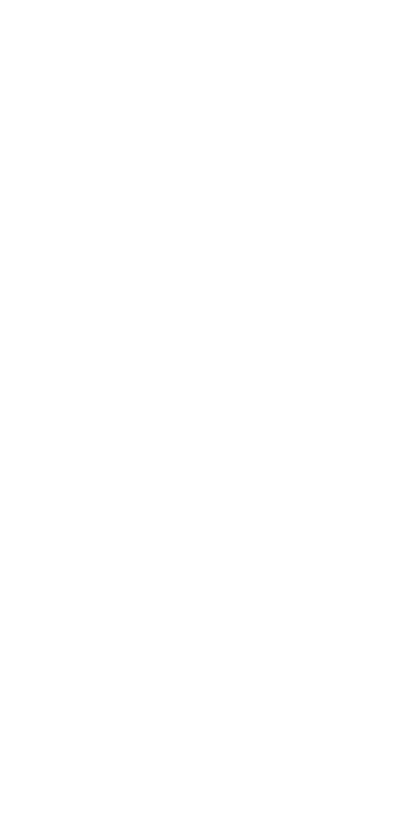
鄭州機場
2.
問題分析
想要給用戶提供一個良好的導(dǎo)航產(chǎn)品,需要解決幾個關(guān)鍵問題:第一,場景所在的地圖是怎么樣的;第二,如何確定用戶的位置;第三,如何使用更加直觀的方式引導(dǎo)用戶走到目的地。這些問題,在通常的室外場景來看,可能都不是"問題",因為可以直接使用現(xiàn)有的地圖、GPS定位、規(guī)劃路線和GPS實時位置引導(dǎo)到達(dá)目的地。但是這些能力在室內(nèi)場景下,卻變得很難。具體原因包括:在室內(nèi)場景中,GPS信號受到建筑物遮擋往往定位不準(zhǔn)確,而現(xiàn)有的Wi-Fi、基站等定位技術(shù)也因場景中基礎(chǔ)設(shè)施情況的不同而表現(xiàn)出精度差異很大;同時,與室外相比,室內(nèi)場景結(jié)構(gòu)復(fù)雜度高、判斷方向難,給用戶引導(dǎo)也帶來很大的挑戰(zhàn)。
為了解決上述問題,給用戶提供更加友好的室內(nèi)導(dǎo)航服務(wù),我們推出了滴滴AR實景導(dǎo)航產(chǎn)品,其主要方案是采用低成本的視覺定位技術(shù)來提升用戶的定位精度,并結(jié)合增強現(xiàn)實技術(shù)來將引導(dǎo)信息顯示到用戶手機上,給用戶提供所見即所得的交互體驗。
3.
技術(shù)挑戰(zhàn)
要想實現(xiàn)一個理想的AR導(dǎo)航系統(tǒng),我們調(diào)研了很多技術(shù)方案,最終選擇了基于視覺的三維重建技術(shù)來解決地圖構(gòu)建和路徑計算的問題、視覺定位技術(shù)來提供更高精度的定位能力以及傳感器位置推算與渲染技術(shù)來實現(xiàn)更加精確的AR交互顯示。雖然上述技術(shù)在學(xué)術(shù)研究領(lǐng)域已經(jīng)有了很多年的研究,并產(chǎn)出了一些相對成熟的方案,但是在實施過程中,也遇到了很多挑戰(zhàn):
1、在三維重建方面
基于視覺的三維重建技術(shù)依賴相機拍攝到的場景圖像進(jìn)行三維結(jié)構(gòu)恢復(fù),一般應(yīng)用于辦公室、公寓等幾百平米的場景內(nèi)。在機場、火車站、商場等超過幾萬平米的大型場景下,會存在人群密集、重復(fù)紋理多、光照變化大、場景空曠、狹長通道等不利于視覺重建的因素,這種超大現(xiàn)實室內(nèi)場景三維重建是業(yè)界難題。
2、在視覺定位方面
室內(nèi)環(huán)境復(fù)雜多樣,室內(nèi)空間布局、拓?fù)湟资苋藶榈挠绊?,?dǎo)致聲、光、電等環(huán)境容易發(fā)生變化,對于以特征匹配為基本原理的定位方法,定位結(jié)果將受到較大影響。機場、火車站、商場內(nèi)大量重復(fù)出現(xiàn)的指示牌、廣告牌都極易產(chǎn)生誤匹配,影響定位的精度。
3、在傳感器位置推算方面
由于傳感器噪聲的存在,使得基于慣性傳感器的位置推算存在累積誤差。當(dāng)長時間使用時,導(dǎo)致導(dǎo)航路線偏離正確路徑,嚴(yán)重影響著用戶體驗。此外,用戶行走行為和手機硬件的多樣性,使得單一模型的慣性傳感器位置推算很難解決所有場景遇到的問題。因此,亟需提出一種模型自適應(yīng)機制來提升導(dǎo)航系統(tǒng)的準(zhǔn)確度和魯棒性。
4.
關(guān)鍵解決方案
為了解決上述問題,結(jié)合具體的應(yīng)用場景以及技術(shù)積累,我們分別針對每個關(guān)鍵模塊進(jìn)行了系列優(yōu)化,現(xiàn)簡要分享一下。
基于視覺的三維重建技術(shù)
三維重建解決的是室內(nèi)地圖構(gòu)建的問題。三維重建一般需要借助運動恢復(fù)結(jié)構(gòu)(Structure from Motion,SfM),其學(xué)術(shù)定義是「在未知的環(huán)境中,讓一個機器人能進(jìn)行環(huán)境的構(gòu)建,并且估計自身的運動」。用通俗的語言講,是利用相機拍攝到的圖像或視頻,恢復(fù)整個場景的三維結(jié)構(gòu)。系統(tǒng)的輸入是多張圖像或視頻流,輸出是場景的三維結(jié)構(gòu)和每張圖像拍攝的位姿。相機位姿是6自由度,3個自由度表示位置,3個自由度表示姿態(tài)(相機朝向)。位置可以理解成三維空間當(dāng)中的一個點,姿態(tài)就是這個相機的朝向,如果在二維上就是360度的朝向,擴展到三維就是一個球體的朝向。
首先我們了解下SfM的技術(shù)框架,一共四個主要步驟:①數(shù)據(jù)采集;②特征提取;③數(shù)據(jù)關(guān)聯(lián);④結(jié)構(gòu)恢復(fù)。在恢復(fù)場景的三維結(jié)構(gòu)時,并不是使用圖像中的所有像素點,而僅從圖像中提取穩(wěn)定、顯著的點,也就是特征點;數(shù)據(jù)關(guān)聯(lián)是確定有共視區(qū)域的兩張圖像中哪些特征點是對應(yīng)的;后續(xù)會借助幾何的方法以及最優(yōu)化技術(shù)(Bundle Adjustment)將這些圖像中的點恢復(fù)為空間的三維點。整個問題最終被轉(zhuǎn)化為大型非線性最優(yōu)化問題求解,優(yōu)化目標(biāo)是重建的三維點重投影到圖像中的位置與圖像中的觀測點位置差最小,也就是最小化重投影誤差。
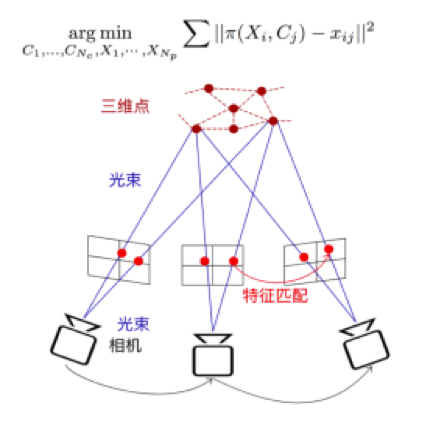
針對大型場站室內(nèi)場景存在的人群密集、重復(fù)紋理多、場景有變化等挑戰(zhàn)。我們設(shè)計了一種基于視覺的大型室內(nèi)場景三維重建方案:針對大型機場、火車站存在的規(guī)模大、場景復(fù)雜(重復(fù)紋理、相似紋理、狹長通道、動態(tài)物體等),提出了一種基于視頻的分塊三維重建方案,首先構(gòu)建圖像間的關(guān)聯(lián)圖,問題可以建模成Graph Cut問題,可以自動進(jìn)行數(shù)據(jù)分塊;之后利用Pose Graph Optimization實現(xiàn)了塊間合并與優(yōu)化,并通過引入關(guān)鍵幀、點云選擇等策略,實現(xiàn)了自動化建圖,效率提升70%,構(gòu)建的超過6萬平米的室內(nèi)場站三維模型是業(yè)界已知的最大單體模型之一,下圖是鄭州機場的三維模型可視化效果。
鄭州機場三維模型
視覺定位技術(shù)
在AR導(dǎo)航的使用場景中,定位的目的就是確定用戶的位置。手機的定位源主要包含3大類:①導(dǎo)航衛(wèi)星接收機:包括中國的北斗,美國的GPS,歐洲的Galileo、俄羅斯的GLONASS等;②內(nèi)置傳感器:包括加速度計、陀螺儀、磁力計、氣壓計、光線傳感器、相機等;③射頻信號:包括Wi-Fi、藍(lán)牙、蜂窩無線通信信號等。除了衛(wèi)星導(dǎo)航接收機外,這些傳感器和射頻信號都不是為定位而設(shè)置的,盡管如此,這些傳感器還是為我們提供了很多的室內(nèi)定位源。主流的全球衛(wèi)星導(dǎo)航系統(tǒng)(Global Navigation Satellite System,GNSS)目前雖然已經(jīng)被大規(guī)模商業(yè)應(yīng)用,在室外開闊環(huán)境下定位精度已能解決大部分定位需求,但該類信號無法覆蓋室內(nèi),難以形成定位。室內(nèi)環(huán)境復(fù)雜,無線電波通常會受到障礙物的遮擋,發(fā)生反射、折射或散射,改變傳播路徑到達(dá)接收機,形成非視距(non line-of-sight,NLOS)傳播。NLOS傳播會使定位結(jié)果產(chǎn)生較大的偏差,嚴(yán)重影響定位精度。
經(jīng)過充分的調(diào)研與對比,考慮到Wi-Fi指紋匹配方式定位精度2~5米,而藍(lán)牙iBeacon作用距離短且布設(shè)成本較高等問題,最終我們采用了視覺定位的方式。該方法基于相機交互的方法,定位精度可達(dá)亞米級,魯棒性較好,且只需利用手機攝像頭、成本較低,無需布設(shè)額外設(shè)備,而且隨著近年視覺定位技術(shù)的不斷優(yōu)化迭代,其精度與魯棒性已完全能滿足室內(nèi)定位的需求。
(1)基于傳感器融合的圖像檢索重排序技術(shù)
通常情況下,用戶手機獲取一張查詢圖后,首先對圖像進(jìn)行特征提取,然后采用特征描述子對特征點進(jìn)行描述,根據(jù)圖中提取的大量2D特征點,會在當(dāng)前場景三維模型中檢索相似的top N張圖像,根據(jù)最相似的圖像進(jìn)一步尋找2D點與模型中3D點的匹配,最后利用RANSAC+PnP求解,計算查詢圖的位置與姿態(tài)[R|t]。
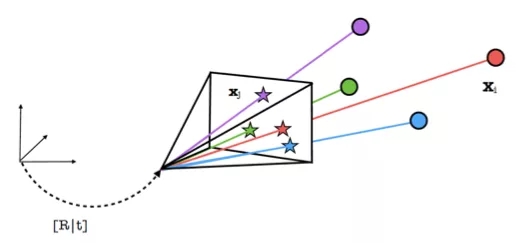
但是由于室內(nèi)場景存在大量人造物體,例如機場、火車站中大量出現(xiàn)的指示牌,商場中大量出現(xiàn)的廣告牌,都很容易因為局部特征相似,導(dǎo)致錯誤的匹配??紤]到手機本身集成了磁力計和GNSS傳感器,雖然這些低成本的傳感器精度有限,但作為定位初值還是可以加以利用,我們根據(jù)磁力計獲取的大致方位,以及GNSS獲取的大致位置作為先驗知識,根據(jù)傳感器的精度指標(biāo),對候選圖像進(jìn)行聚類,并將參數(shù)加權(quán)帶入圖像重排序(rerank)的計算公式,可以剔除具有明顯方向差異或者位置差異顯著的候選圖像。在降低誤匹配概率的同時,也顯著提高了計算的效率,保證了定位結(jié)果的精度。
(2)基于上下文信息的位姿校正技術(shù)
由于室內(nèi)人造結(jié)構(gòu)的特殊性,很多場景都是對稱修建或者呈規(guī)則排列的幾何布局,導(dǎo)致在視覺定位的時候,不僅是局部特征幾乎一致,甚至大范圍場景內(nèi)的全局特征也是非常相似的,這就導(dǎo)致初始定位存在一定概率的誤匹配情況。當(dāng)用戶剛好位于此類區(qū)域的時候,很有可能會得到錯誤的引導(dǎo)信息。不過在實際情況中,這些容易混淆的區(qū)域不會完全一模一樣,當(dāng)用戶移動一小段距離或者視角發(fā)生變化的時候,往往會出現(xiàn)具有顯著區(qū)分度的地物特征,依賴這些信息可以對用戶當(dāng)前的位姿進(jìn)行校正,重新生成一條正確的引導(dǎo)路線。但是同樣是特征匹配,當(dāng)前后兩幀信息都滿足定位條件,但定位結(jié)果存在較大差異的時候,如何分辨究竟哪個是正確的結(jié)果呢。這時就需要利用到上下文的信息,即我們在定位的時候并不完全依賴于一次的定位結(jié)果,而是一片區(qū)域或者一段軌跡中的多個定位結(jié)果,當(dāng)這些結(jié)果呈現(xiàn)出較好的一致性的時候,通常有更大的概率是正確的定位,相反,那些局部特征相似的區(qū)域,由于匹配到了錯誤的參考圖像,其結(jié)果往往呈現(xiàn)出孤立的跳變,與前后幀并不能平滑過渡,行走軌跡也是不光滑的。利用這種定位結(jié)果的上下文信息,可以有效檢測出錯誤的定位結(jié)果,對其進(jìn)行過濾,或者及時發(fā)現(xiàn)當(dāng)前已經(jīng)處于錯誤的引導(dǎo)路線上,根據(jù)正確的結(jié)果進(jìn)行校正。

傳感器位置推算技術(shù)
在完成視覺定位后,需要根據(jù)手機的位置進(jìn)行實時的路線指引和渲染,這里我們使用了基于傳感器的位置推算技術(shù),通過讀取手機上的傳感器信息并結(jié)合人體運動模型等方法,推算出對應(yīng)的位置。
慣性傳感器包括加速度計和陀螺儀,通常還會與磁力計組合使用。每個傳感器均具有三個自由度。加速度計測量施加給移動設(shè)備的加速度讀數(shù),陀螺儀測量移動設(shè)備的旋轉(zhuǎn)運動,磁力計通過感知磁場的變化,推理出用戶當(dāng)前的朝向。這些傳感器可以在沒有外部數(shù)據(jù)的情況下確定移動設(shè)備的位置,而不需要基礎(chǔ)設(shè)施的輔助?;趹T性傳感器的位置推算由于以下優(yōu)點逐漸成為研究的熱點:①低能耗全天24小時運行;②不受外界環(huán)境干擾;③內(nèi)置于每一部移動智能終端。
現(xiàn)有的基于積分的慣性導(dǎo)航算法主要利用線性加速度計讀數(shù)(加速度計讀數(shù)減去重力數(shù)據(jù))進(jìn)行二次積分得到位移和陀螺儀讀數(shù)積分得到姿態(tài),繼而解算當(dāng)前位置。然而,慣性傳感器具有噪聲,導(dǎo)致慣性積分算法估計的位置很快飄移。因此,當(dāng)前慣性積分算法主要應(yīng)用于高精度慣性器件中,例如航天級別的慣性傳感器。為了解決在低端手機中慣性傳感器的迅速飄移問題,研究者們提出了PDR (Pedestrian Dead Reckoning) 算法。
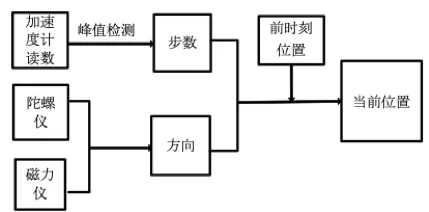
PDR (Pedestrian Dead Reckoning) 算法是一種基于相對位置的位置推算方法,主要思想是給定初始位置和朝向,根據(jù)行走的位移推算出下一步的位置。主要包括計步、步長估計和朝向估計模塊,如下圖所示。計步主要是通過檢測加速度計讀數(shù)的峰值點實現(xiàn)步子識別;步長估計利用一步之內(nèi)的加速度計讀數(shù),根據(jù)人的身高、體重、步頻等特征擬合當(dāng)前一步的步長;朝向估計利用加速度計和陀螺儀讀數(shù),通過濾波或者優(yōu)化技術(shù)實現(xiàn)設(shè)備的姿態(tài)估計,繼而獲取當(dāng)前一步的行走朝向。由于上述每一個模塊都會有誤差,且對不同的人群和設(shè)備的多樣性比較敏感,隨著時間的推移,誤差累積增大,直至導(dǎo)航系統(tǒng)不可用,為AR引導(dǎo)帶來了技術(shù)挑戰(zhàn)。
為了解決上述技術(shù)挑戰(zhàn),我們提出了魯棒的位置推算算法,該方法發(fā)表在機器人領(lǐng)域頂級會議International Conference on Intelligent Robots and Systems (IROS) 2020上。
所提出的方法主要包括基于步態(tài)強度的計步算法,基于步頻和統(tǒng)計特征的步長估計算法,基于深度模型的朝向回歸算法和基于機器學(xué)習(xí)的運動分類算法。下面介紹一下相關(guān)算法。
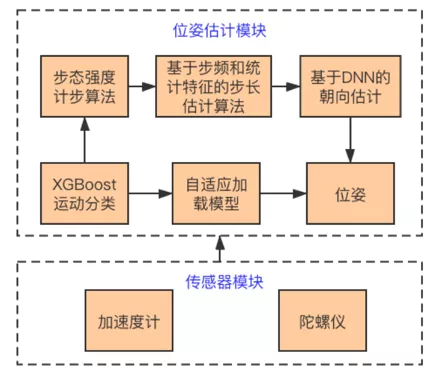
(1)基于步態(tài)強度的計步算法
給定三軸加速度計讀數(shù),首先對每一幀加速度計讀數(shù)求取幅值。利用當(dāng)前幀加速度計的幅值和其鄰近數(shù)據(jù),檢測加速度計讀數(shù)波形的峰值,每一個峰值對應(yīng)著候選步子,如下公式所述:
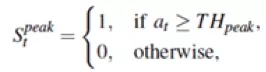
其中,S表示當(dāng)前加速度計讀數(shù)的狀態(tài),即是否為候選步子,如果為1,則表示當(dāng)前時刻檢測到候選步子。
其次,根據(jù)長短窗內(nèi)的加速度計讀數(shù)的均值來判斷當(dāng)前時刻是否為候選步子,其下公式所述:
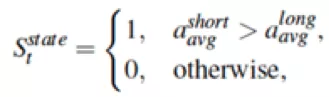
其中表示短窗口內(nèi)的加速度計讀數(shù)的均值,表示長窗口內(nèi)的加速度計讀數(shù)的均值。
再次,根據(jù)加速度計數(shù)據(jù)計算步態(tài)強度,它描述了一步之內(nèi)加速度的變化情況。當(dāng)步態(tài)強度超過一定闕值后,我們認(rèn)為當(dāng)前時刻是候選步子:
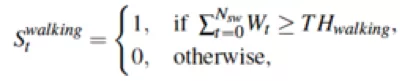
其中,
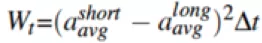
下圖展示了真實行走狀態(tài)下步態(tài)強度的變化情況,其中藍(lán)色點表示步態(tài)強度,紅色點表示步點。
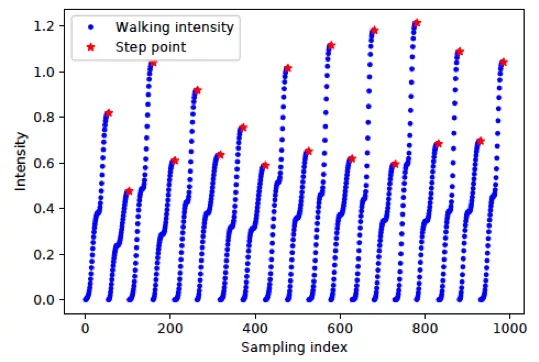
最后,當(dāng)上述狀態(tài)均取得1時,認(rèn)為當(dāng)前時刻為檢測到一步,計算公式如下:
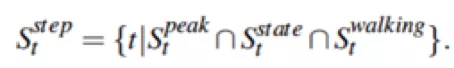
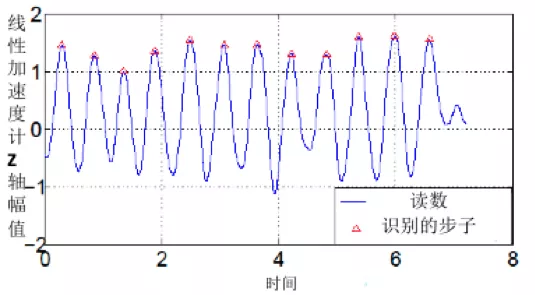
計步算法示意圖如下圖所示,其中藍(lán)色曲線表示加速度計讀數(shù),紅色三角形表示識別到一步。
(2) 步長估計算法
我們提出了一種基于統(tǒng)計特征的步長估計算法,其中統(tǒng)計特征包括步頻、一步內(nèi)的加速度計讀數(shù)的方差、極差的n次開方,計算公式如下所述:
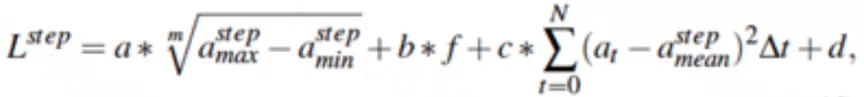
其中,a, b, c和d是超參數(shù),根據(jù)實際應(yīng)用進(jìn)行訓(xùn)練。f表示行走步頻,表示加速度計讀數(shù)極差的m次開方,表示加速度計讀數(shù)的方差。
(3)朝向估計算法
現(xiàn)有的朝向估計算法利用互補濾波和卡爾曼濾波實現(xiàn)設(shè)備朝向的估計,而設(shè)備朝向和人員行走朝向之間存在變化的偏差角會導(dǎo)致PDR的位姿估計累積飄移。為了解決該問題,我們利用深度學(xué)習(xí)算法來回歸用戶行走的朝向。具體而言,我們提出了一種heading-confidence模型,采用LSTM和ResNet作為深度網(wǎng)絡(luò)框架。LSTM主要負(fù)責(zé)行走朝向的回歸,ResNet主要負(fù)責(zé)行走速度的回歸,最后,我們設(shè)計了置信度函數(shù)來進(jìn)行朝向的融合。
(4) 運動分類
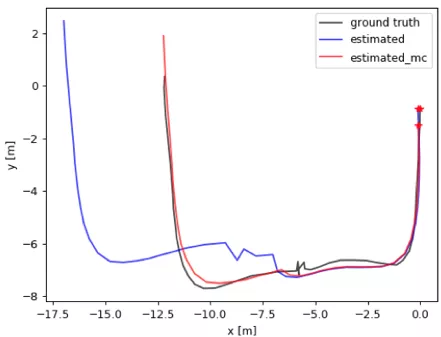
為了提升PDR系統(tǒng)對運動類別的魯棒性,我們設(shè)計了一種基于梯度提升決策樹算法的運動分類模型。主要包括行走、隨意行走、靜止和手持設(shè)備搖擺四種姿態(tài)。通過識別不同的行走姿態(tài),我們自適應(yīng)的加載對應(yīng)的模型參數(shù),繼而提高了PDR算法的精度。實驗結(jié)果如下圖所示。其中,黑色曲線表示參考真值,藍(lán)色曲線表示沒有運動分類的PDR算法軌跡,紅色曲線表示引入了運動分類的PDR軌跡。可以看到,紅色軌跡更加接近于參考真值。
5.
總結(jié)
大型機場、商場、火車站內(nèi)部的上車點引導(dǎo)能力對用戶體驗影響很大,為了解決這個問題,地圖團(tuán)隊做出了很多努力,推出了“圖文引導(dǎo)”方案來使用圖像和文字的方式幫助用戶。同時,為了給用戶提供更好的體驗,我們也推出了滴滴AR實景導(dǎo)航產(chǎn)品,使用人工智能算法等科技手段,為用戶提供準(zhǔn)確的、易用的導(dǎo)航產(chǎn)品,來幫助用戶更快的找到上車點。目前在鄭州、深圳以及日本東京等24個機場、商場或者火車站上線了AR導(dǎo)航服務(wù),數(shù)據(jù)顯示,它能幫助用戶節(jié)省近四分之一的時間,讓他們更便捷地到達(dá)上車點。與此同時,在南京火車站等大型場站,我們正在進(jìn)一步探索基于AR導(dǎo)航的技術(shù)來幫助乘客快速抵達(dá)公交站點。后續(xù)我們將持續(xù)優(yōu)化和打磨我們的算法,為乘客和司機創(chuàng)造更多的價值。歡迎大家體驗我們的產(chǎn)品,并對我們提出寶貴的意見,希望通過我們的努力可以為大家提供更好的出行體驗。





